AWS Use Cases
Explanations and use cases of some AWS services.
Serverless application to process data based on changes done in DynamoDB
Scenario:
SQL databases has triggers which help us act based on any update CRUD operations done on a record. Same option is not directly available in noSQL databases.
Solution:
In NoSQL databses, this can be achieved in different ways. I will explain one solution using dynamoDB.
Services Consumed:
- DynamoDB
- Lambda
- Kinesis Streams
- SQS (Simple Queue Service)
- CloudWatch
Serverless Architecture:
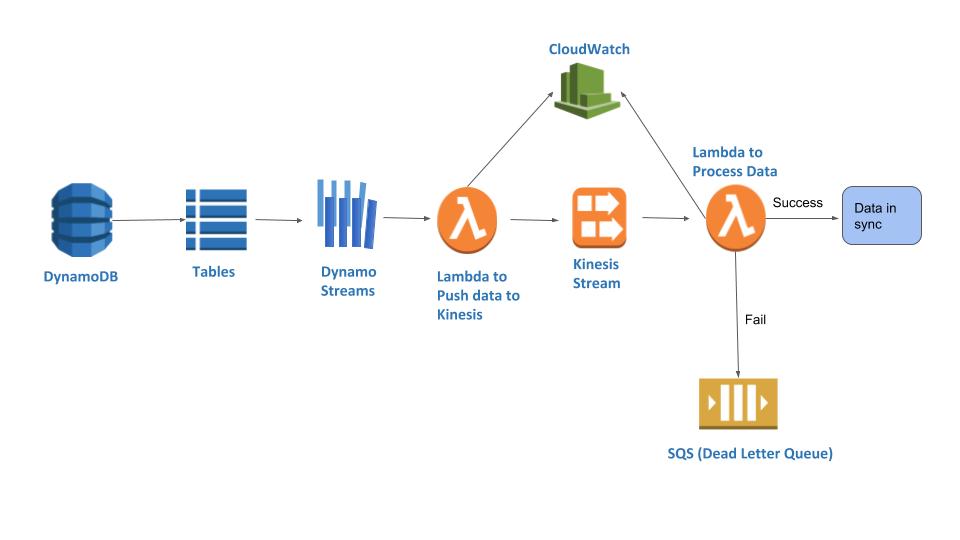
Explanation:
DynamoDB:
DynamoDB is a NoSQL database service from Amazon which supports key-value and document data structures.
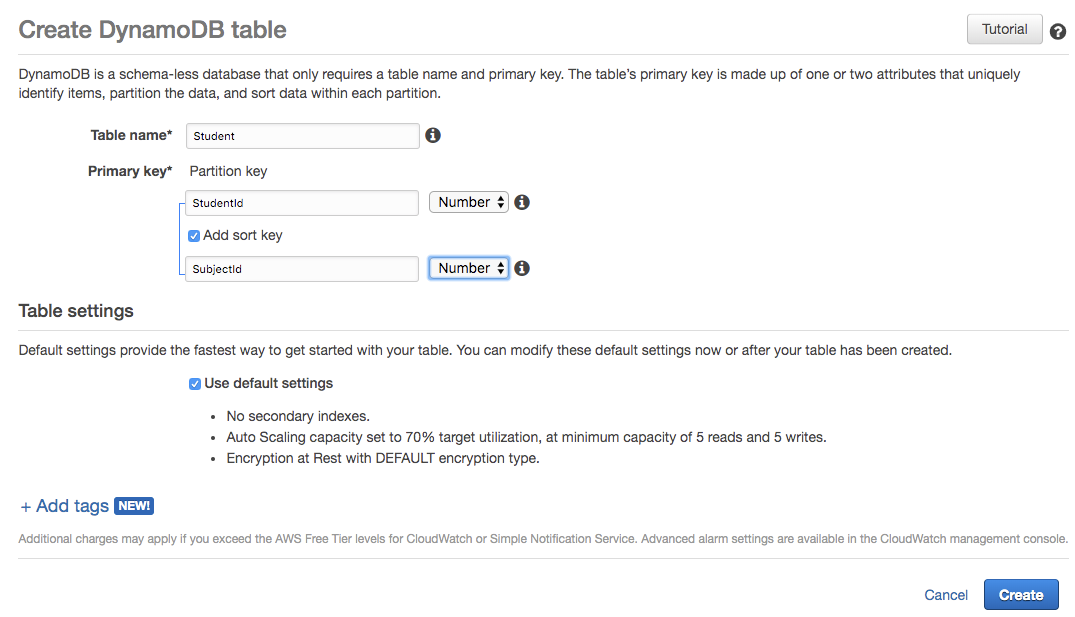
When you login to AWS, look for DynamoDB under Services. Once you are in DynamoDB, click on Create table, button which will allow you to create a table. Provide a table name and Primary Key which will be used for basic indexing of the data. The primary key cannot be duplicate. You can also provide a sort key in addition to the primary key if the primary key won't be unique in all cases. For example, StudentId and SubjectId, where one student can have multiple subjects assigned.
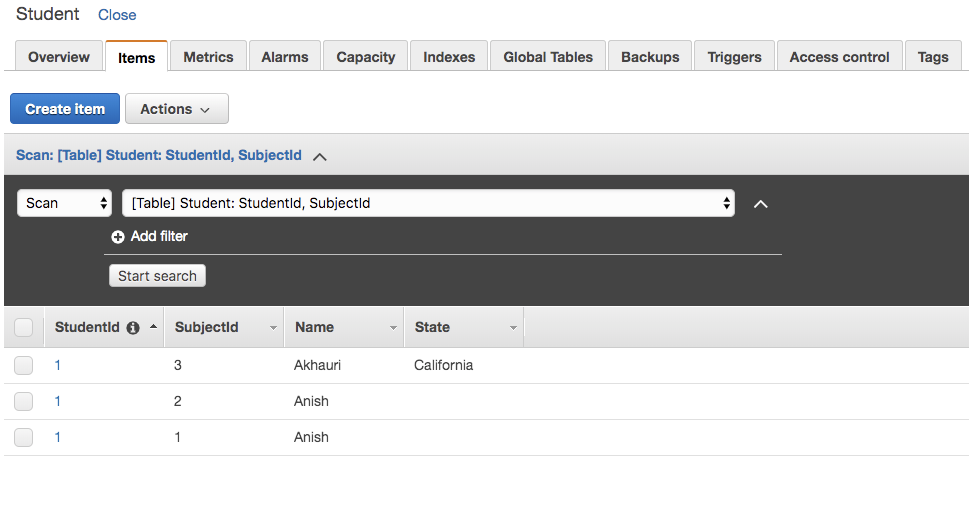
Once the table is created you can start adding records into the table. Navigate to Items table and click on Create item button to add a record.
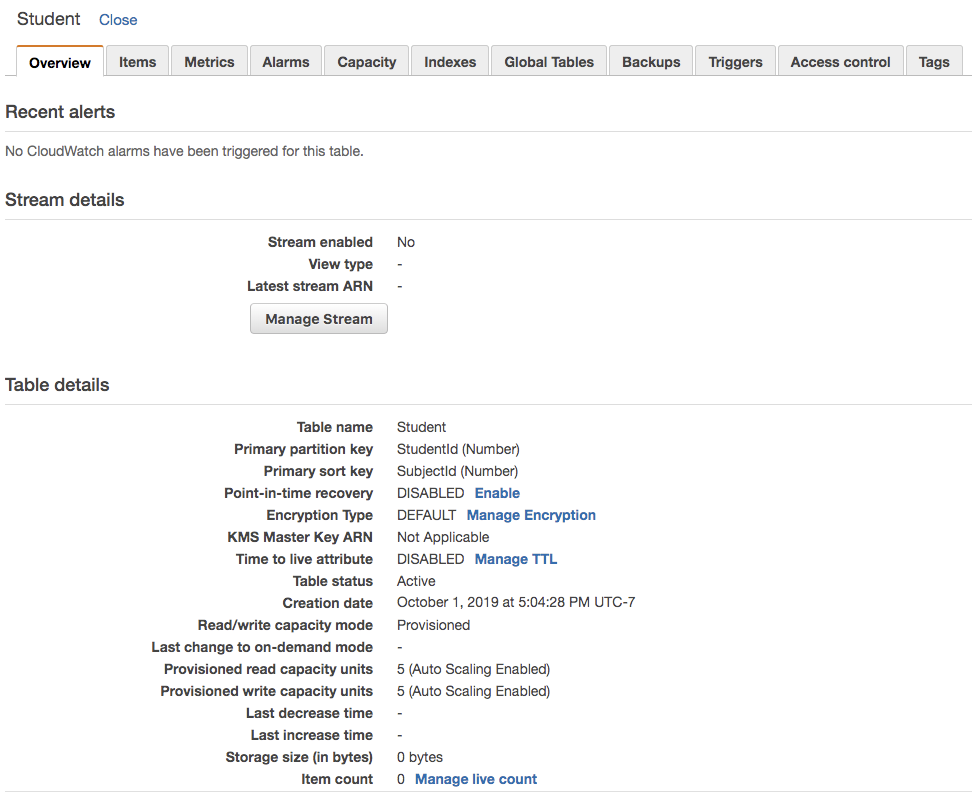
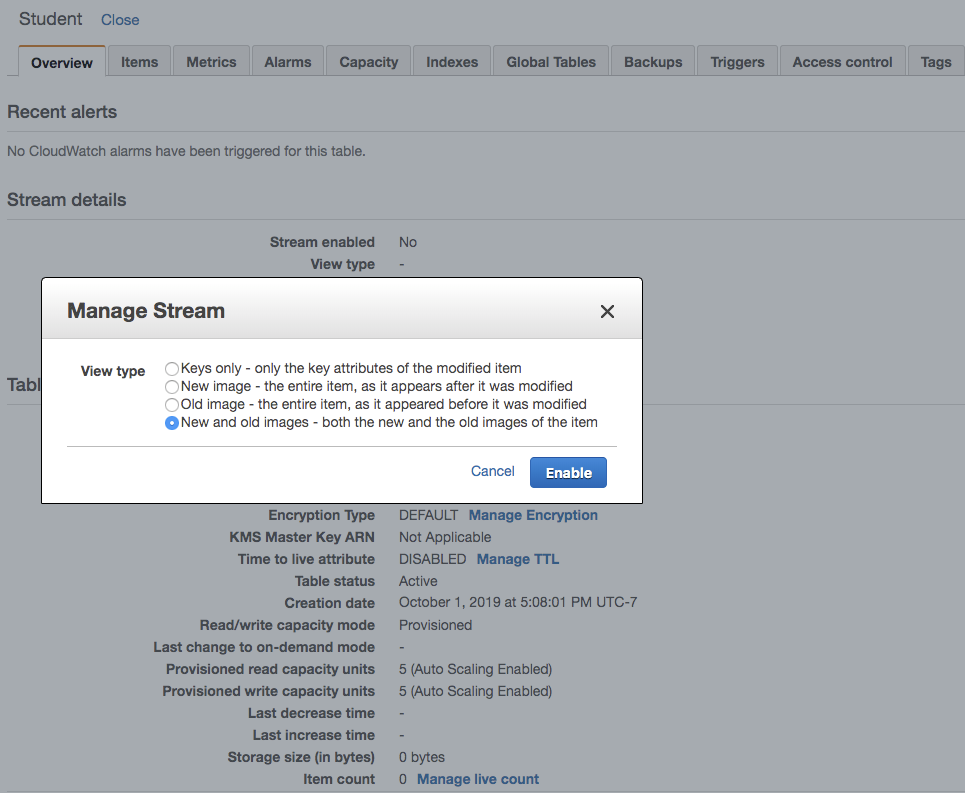
Now we will enable the dynamo stream for this table. Navigate to Overview tab of the table, you can see Stream enabled as No. To enable the stream, click on Manage Stream button. This will show following 4 options:
- Keys only
- New image
- Old image
- New and old image
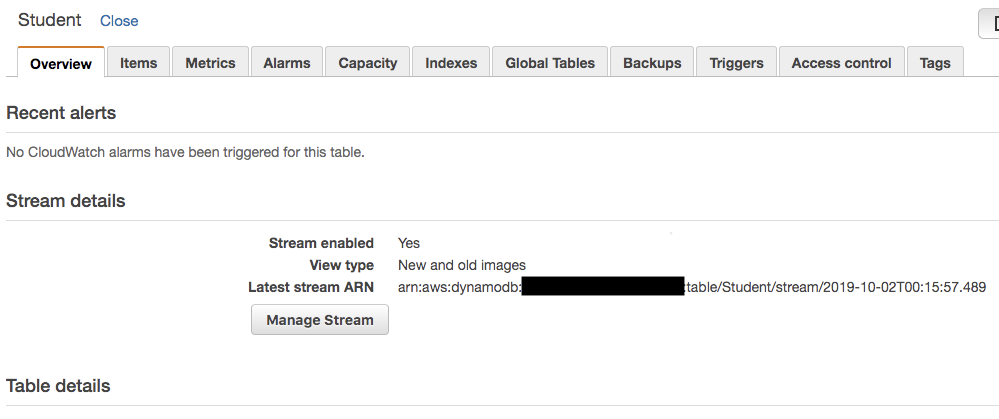
Now we have created a table and enabled streams to that dynamo table. This dynamo stream need to trigger a lambda which can do further proessing. We will learn how to create a lambda and link it to the dynamo streams.
Lambda:

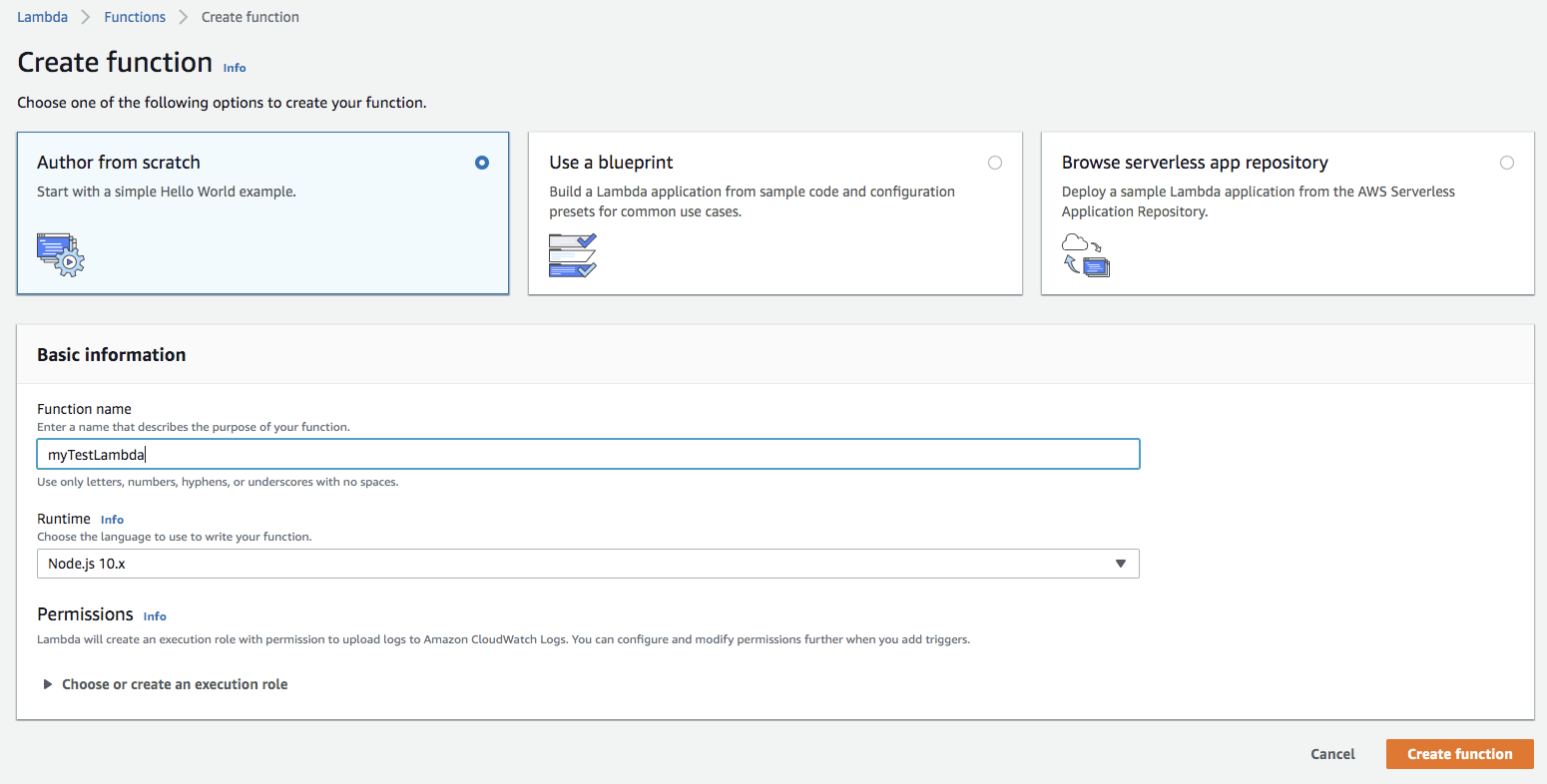
To create a lambda, search lambda under aws service. Once lambda console, is loaded you will see all the lambdas present under the account and region. Click Create function button. Here we get 3 options, either to write the lambda from scratch or use a blueprint available in amazon, or any existing serverless app in respository. I am going to select the option Author from scratch. Provide a function name and chose any of the supported language from Runtime. I am chosing NodeJs here.
Once you click on Create Function, a function will be created without any functionality. We need to implement the functionality inside this. The lambda console gives users ability to write the code or upload the code. We will write a simple code here.
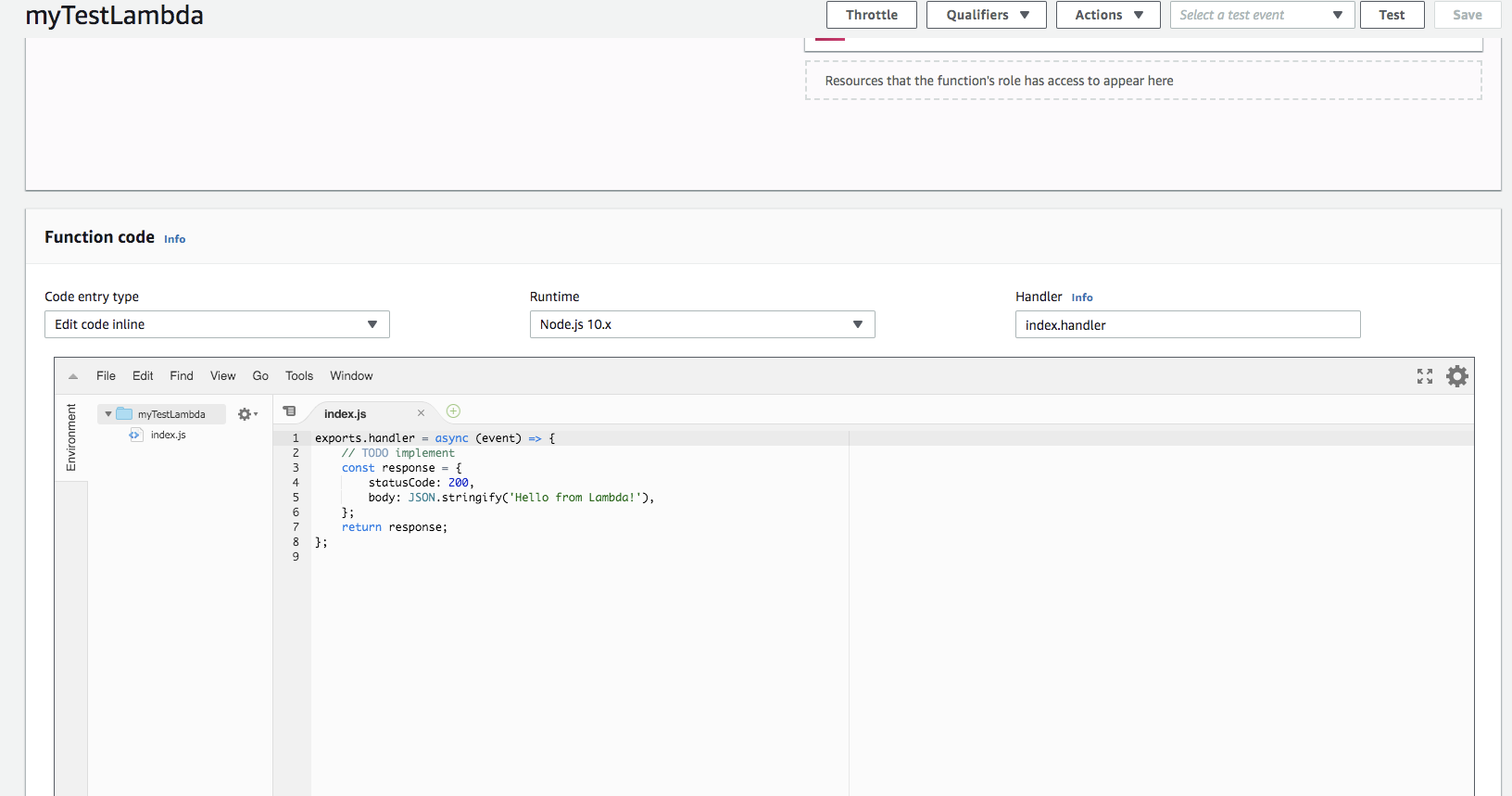
Find below the simple code for lambda, you can notice here, we have added a kinesis stream name, we will create a kinesis stream with the same name to which lambda will push the data.
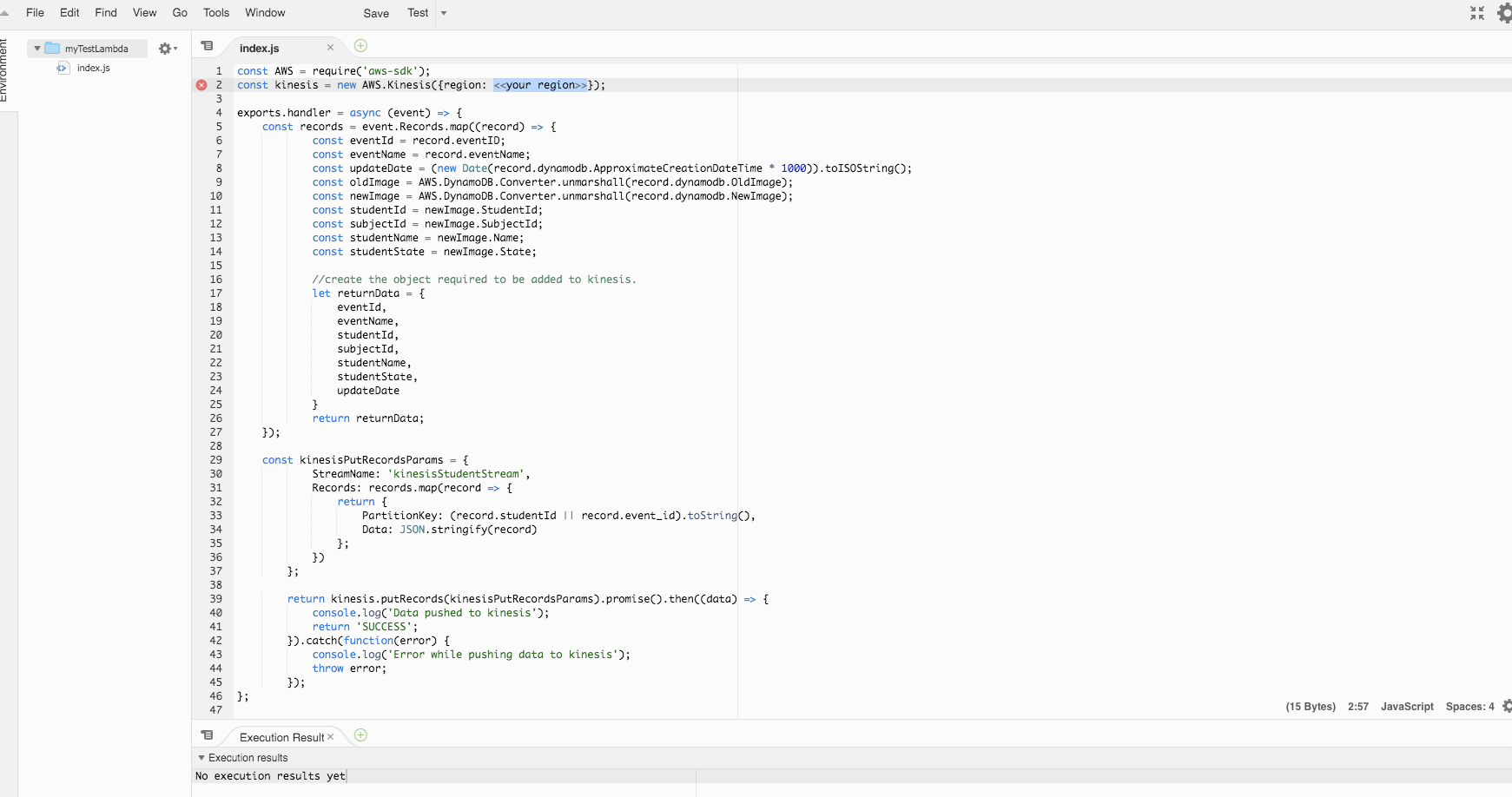
You can see the above code in my git repo.
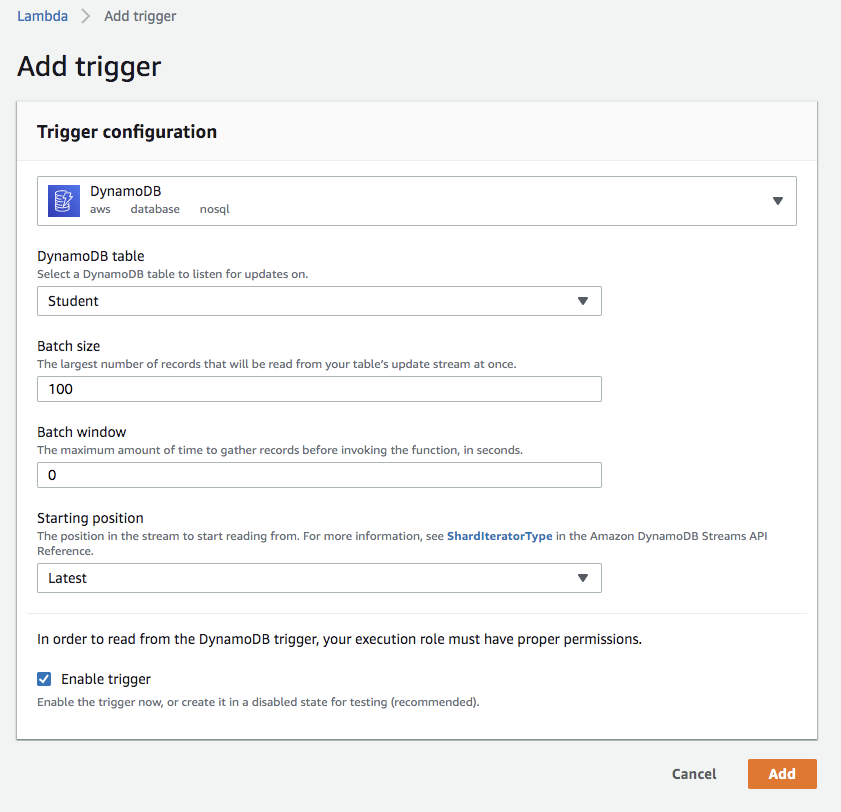
Now we need to link this lambda to dynamo stream, so that whenever there is a change in our Student table, it triggers the lambda. To enable the trigger click on button Add trigger. It will open a Trigger Configuration page. Select DynamoDB from Select a trigger dropdown. Then select the Student table from the DynamoDB table dropdown. You can also select the batch size and window to give the maximum batch size or time to gather the records before invoking the lambda function. Click on Add button to enable the trigger.
The kinesis stream will be enabled and can be seen in the Designer. Now the lambda is listening to the stream and is ready to push data to kinesis.
Let's create the kinesis stream.
Kinesis Streams:
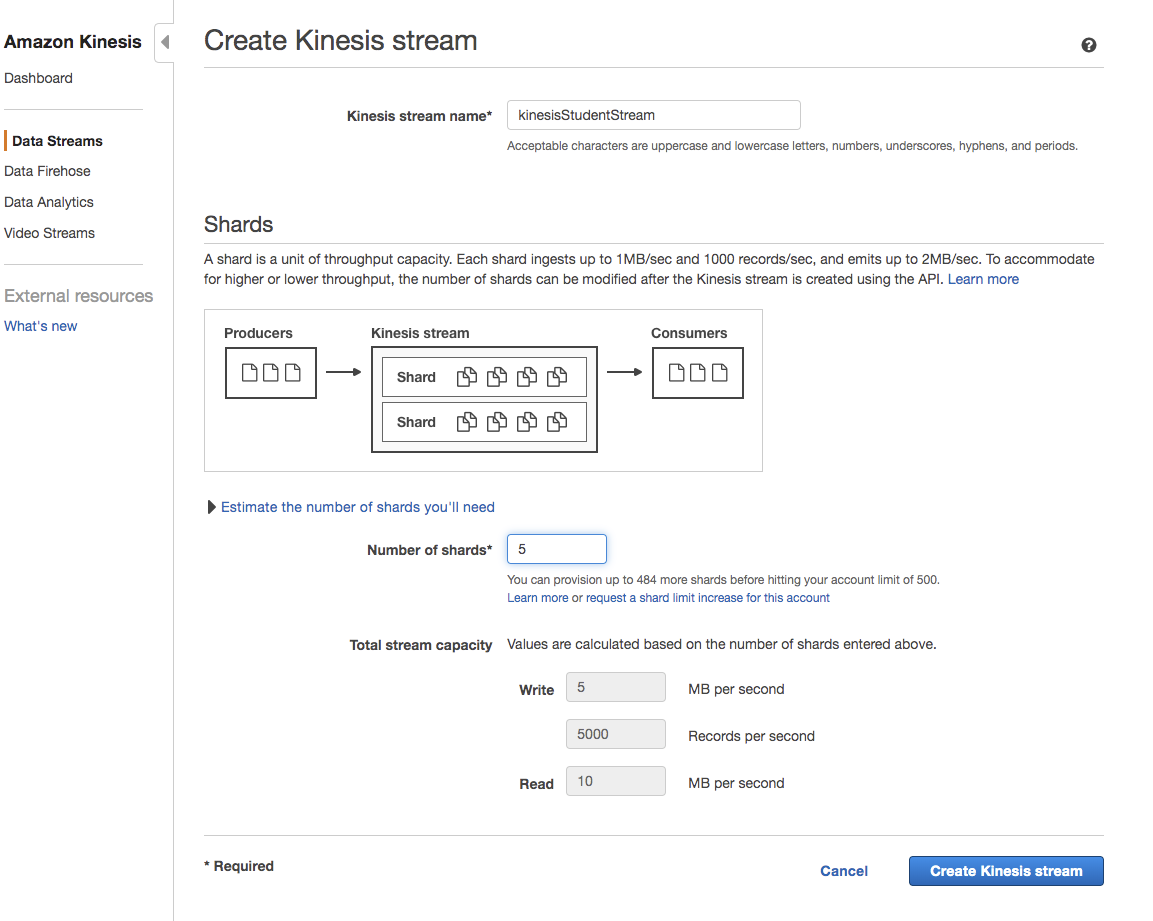
Navigate to Services, look for kinesis. It will lead you to Kinesis console. Select Data Streams from the left side bar. Click button Create kinesis stream.

Provide the kinesis name kinesisStudentStream and Number of Shrads needed. The shrads impacts the cost of the stream heavily, so we need to select proper shrad numbers.
There is a calculator available in the console to estimate the shards required by your application.
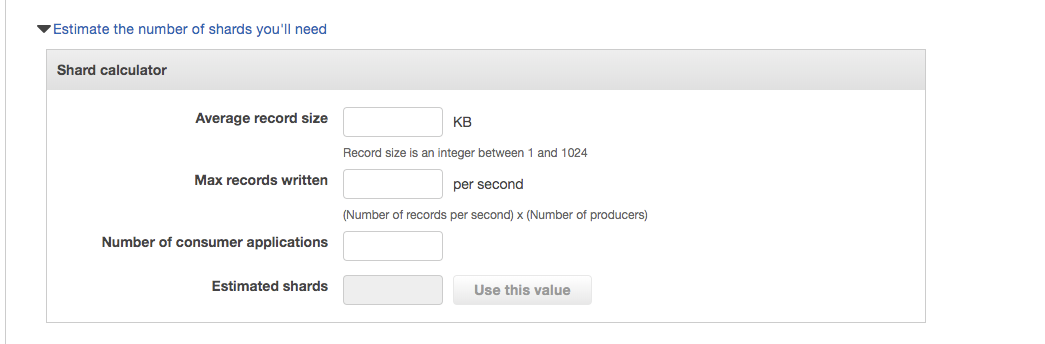
As per AWS documentation, a shrad is defined as:
There might be scenarios where lambda fails due to reasons which might solve on its own if we do a re-try. Its always good to have a re-try mechanism in place. If there are issues which won't get resolved on its own, then its a good idea to put the failed data somewhere for further analysis. We will use SQS - Simple Queue Service as Dead Letter Queue.
SQS (Simple Queue Service):
SQS is a queue service where we can put the failed records for further analysis. We can use SQS as well for the purpose we use kinesis. But the reason for me to select kinesis here is the ability of kinesis to be consumed by multiple application while maintaining the order of the data.
We will use SQS to keep track of failed records, we can enable re-tries in SQS so that SQS will trigger the lambda again for the failed records and then will send it to its dead letter queue. SQS can be created in 2 forms:
- Standard Queue
- FIFO Queue
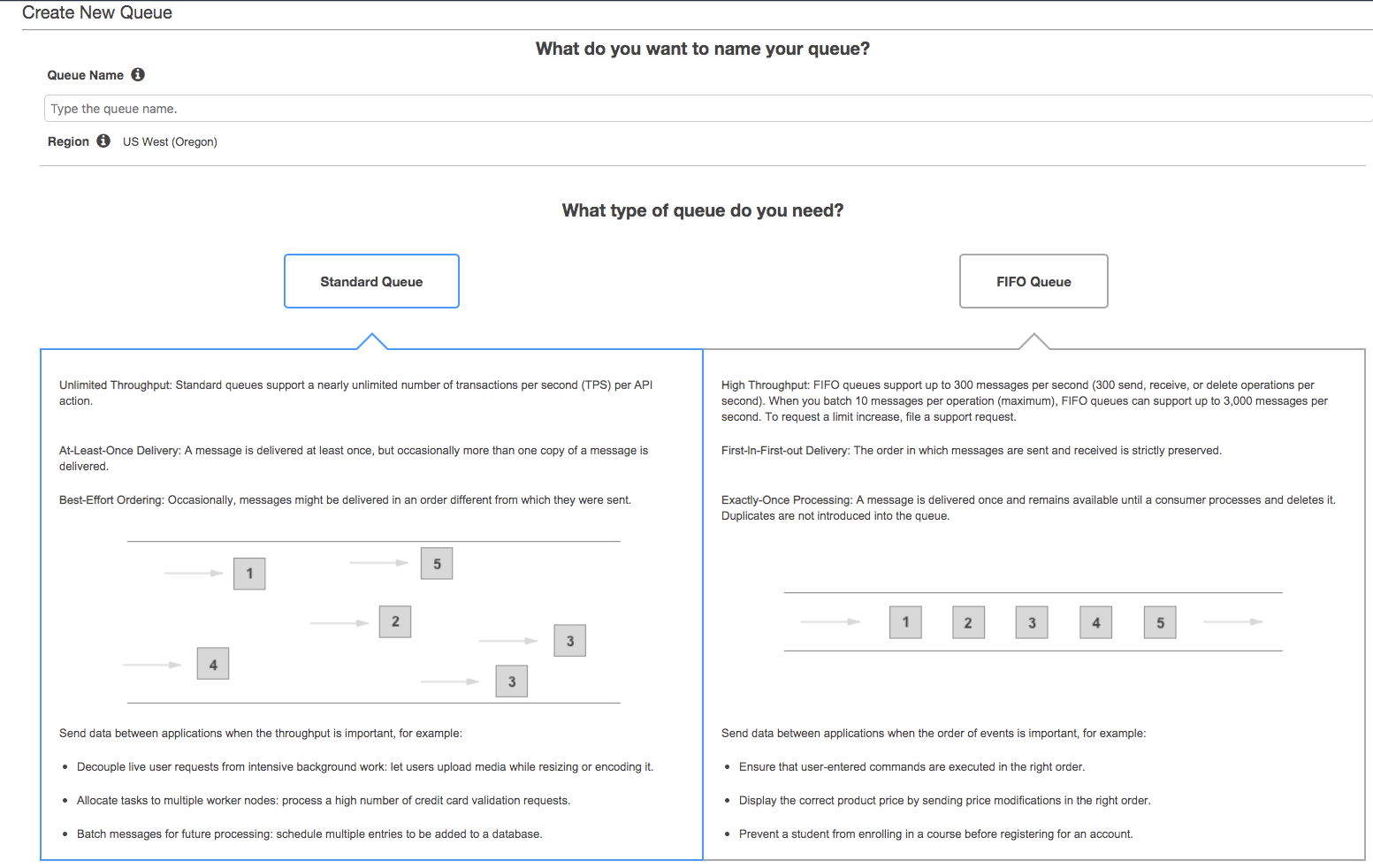 There are many other parameters to configure the SQS queue, like message retention, max message size, etc.
There are many other parameters to configure the SQS queue, like message retention, max message size, etc.
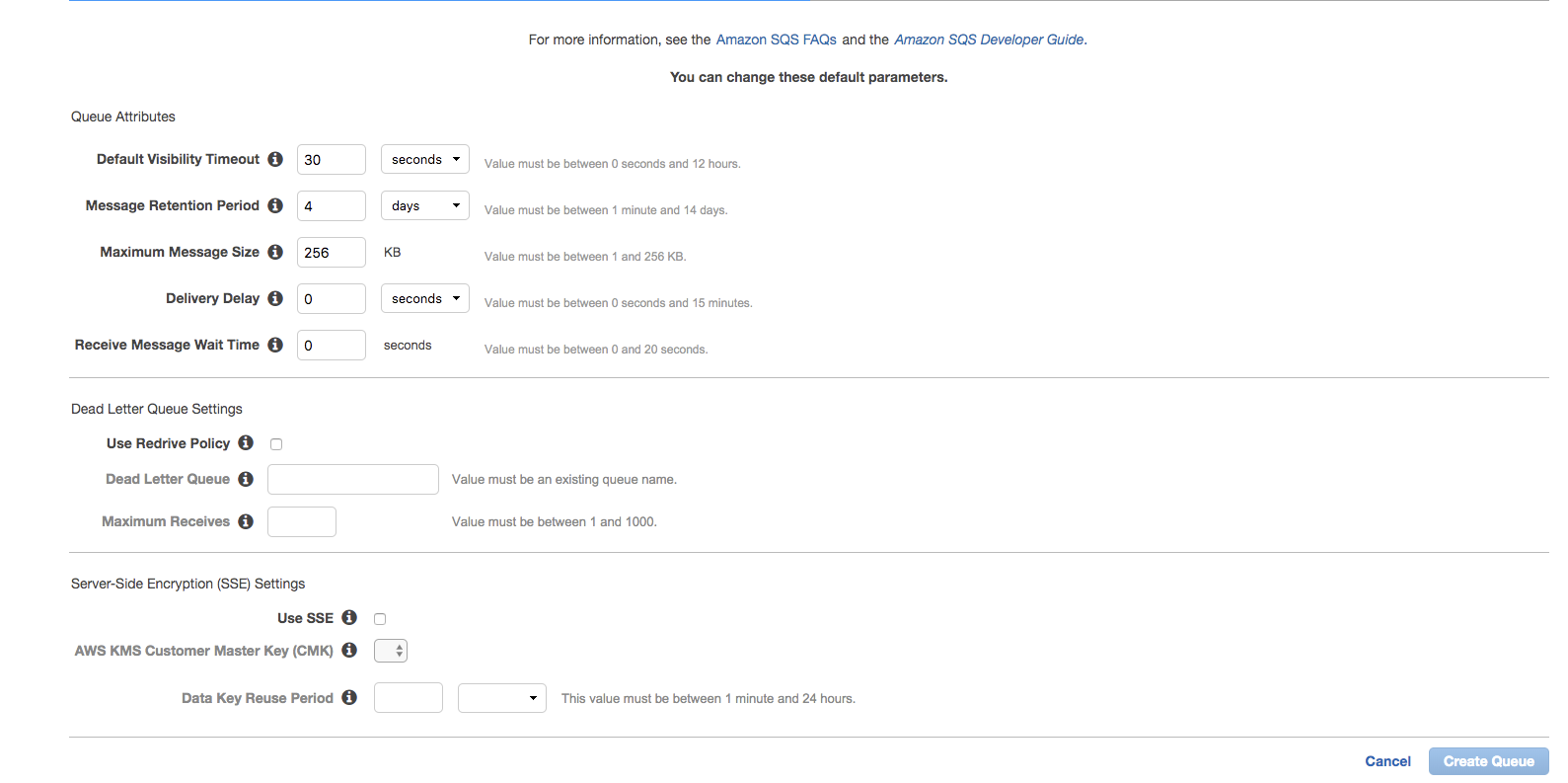
Once the queue is created, we can update the lambda to send the requests to SQS in case of failures. Also, we can add a trigger to the other lambda, which will allow the lambda to be invoked through the messages in SQS.
Lambda automatically creates a log group for cloudwatch, which will log each console.logs to cloud watch. Now the whole serverless pipeline is ready, and each modification/inerstion/deletion done on dynamoDB table will trigger a call to lambda, which does needed work.

